stm32
maven
云计算
binder协议
DOM型XSS
simulink
文字
CVE-2022-27925
AI绘画 神经网络
iot
电池
产品经理常犯的错误
skill 命令
魔百盒固件
堆排序
pthread
uart串口通信
清华大学
YOLOX
Conditional注解
storm
2024/4/11 16:17:31

storm集群安装配置:
1:首先安装zookeeper集群
2:安装storm:
tar -zxvf apache-storm-1.2.2.tar.gz -C /usr/local
sudo mv apache-storm-1.2.2 storm
3:更改conf目录下storm.yarml配置文件
sudo vi storm.yarml
########### These MUST be filled in for a …
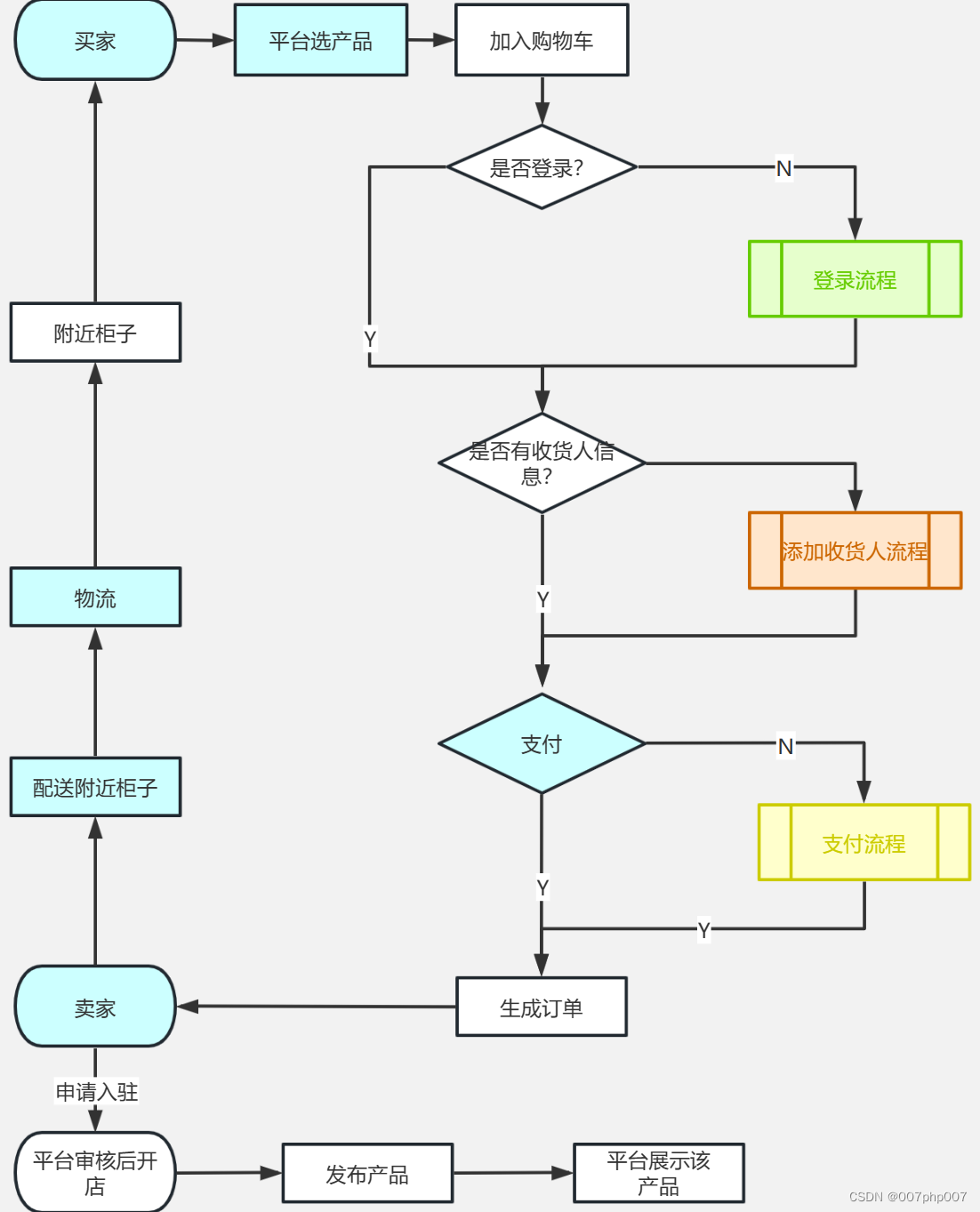
智能柜架构解析与实践探索——打造智能化、高效的物品存储管理系统
在物联网和人工智能技术的快速发展下,智能柜作为智能化物品存储管理系统,正在逐渐走进我们的生活和工作场景。本文将深入探讨智能柜的架构设计原理、核心技术和实践经验,带领读者了解如何构建智能、高效的智能柜系统,提升物品管理…
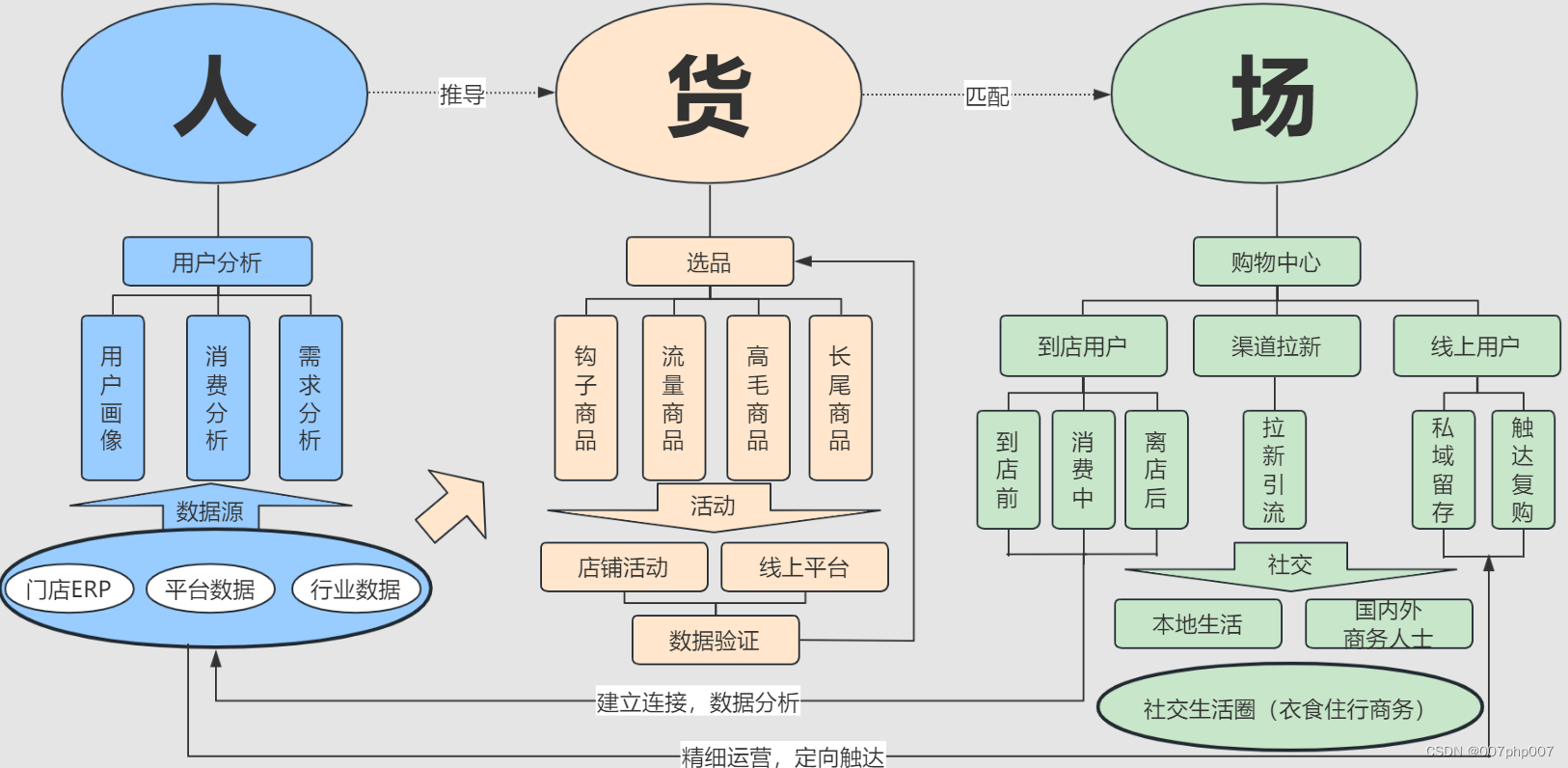
构建未来新零售平台的设计与实现的总结
随着科技的飞速发展和消费者需求的不断变化,新零售已经成为零售行业的新趋势。在这个数字化时代,构建一个高效、智能、一体化的新零售平台架构至关重要。本文将探讨如何设计和实现一个具备创新性和竞争力的新零售平台。
引言: 新零售是指利用…
Storm+Kafka+Redis+zookeeper docker集群实战问题与解决
目录 引言
问题与解决 引言 下面的错误主要是在完成大数据展屏时遇到的一些报错,从最开始的storm构建rowkey,hbase实现统计到storm直接统计redis存结果,第一种方式是参考的一本storm实战书籍,但是老师说这种方法无法发挥storm的并…
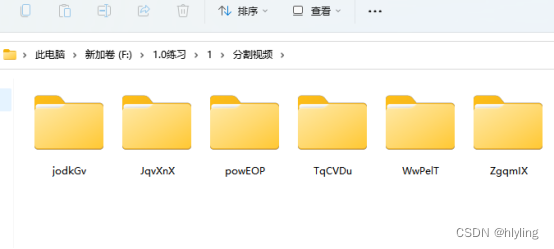
文件夹改名利器!批量随机重命名并自定义长度
你是否曾经为如何快速有效地重命名多个文件夹而感到困扰?我们为您带来了一款强大的文件夹改名工具,让您轻松实现批量随机重命名,并自定义长度,让您的文件夹管理更加高效便捷 首先第一步,我们要打开文件批量改名高手并登…

Apache Storm学习笔记(1)流计算概述
静态数据和流数据
静态数据是静止不动的,不变化的,历史的数据,一般来说像数据仓库存储的大量历史数据就是静态数据,通过数据挖掘等技术来获取数据信息流数据是大量,快速,随时间变化,持续到达&a…
Storm编程demo
任务:将得到的字符串更改为大写,添加后缀后写入文件
1:spout类
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import or…
kafka storm报错
nimbus配置有误,或链接网络超时 java.lang.RuntimeException: org.apache.thrift7.transport.TTransportException: java.net.ConnectException:
at backtype.storm.utils.NimbusClient.<init>(NimbusClient.java:36)
at backtype.storm.utils.NimbusClient.…
storm Async loop died! reconnect
storm 在有supervisor重启的时候,topology报错,导致所有spout不消费: 2015-07-15T09:48:26.4700800 b.s.util [ERROR] Async loop died!
java.lang.RuntimeException: java.lang.RuntimeException: Client is being closed, and does not tak…
Spark, Storm, Flink简介
目录 1.Spark VS Storm2.Storm VS Flink 本文主要介绍Spark, Storm, Flink的区别。
1.Spark VS Storm
Spark和Storm都是大数据处理框架,但它们在设计理念和使用场景上有一些区别:
实时性:Storm是一个实时计算框架,适合需要实时…

storm drpc
转 http://www.cnblogs.com/panfeng412/archive/2012/07/02/storm-common-patterns-of-distributed-rpc.html 本文翻译自:https://github.com/nathanmarz/storm/wiki/Distributed-RPC,作为学习Storm DRPC的资料,转载必须以超链接形式标明文章…
大数据-Storm流式框架(七)---Storm事务
storm 事务 需求 storm 对于保证消息处理,提供了最少一次的处理保证。最常见的问题是如果元组可以被 重发,可以用于计数吗?不会重复计数吗? strom0.7.0 引入了事务性拓扑的概念,可以保证消息仅被严格的处理一次。因此可…
storm安装手册及笔记
图解Storm相关概念 图解storm的并发机制 安装Storm的步骤
1、安装一个zookeeper集群
2、上传storm的安装包,解压
3、修改配置文件storm.yaml
#所使用的zookeeper集群主机 storm.zookeeper.servers: - "weekend05" - "weekend06"…

【FineReport】--填报报表
制作流程 填报报表,就是对数据集的增删改。 控件类型 行式填报报表
行式填报报表,就是在行市报表中,增加了写入和删除功能
制作行式填报报表
数据集:select * from S产品 limit 5
设计样式如下:
预览效果如下&a…
storm文档(10)----容错
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41578517
源地址:http://storm.apache.org/documentation/Fault-tolerance.html 本文主要介绍Storm作为容错系统的设计细节。 当worker死掉时会发生什么? 当worker死掉时…
storm 文档(2)----基本原理
storm 文档(2)----基本原理
源地址:http://storm.apache.org/documentation/Rationale.html 过去十年间,很多数据处理解决方案不停涌现。 MapReduce、Hadoop以及相关技术使得存储和处理数据在规模上是以前不可想象的。不幸的是&a…
storm文档(4)----开发环境环境搭建
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41519053
源地址:http://storm.apache.org/documentation/Setting-up-development-environment.html 本文大体介绍了如何搭建Storm开发环境。总的来说,步骤如下ÿ…
大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
个人观点:大数据我们都知道hadoop,但并不都是hadoop.我们该如何构建大数据库项目。对于离线处理,hadoop还是比较适合的,但是对于实时性比较强的,数据量比较大的,我们可以采用Storm,那么Storm和什…
SparkStreaming,Flink,Storm三大实时框架对比分析
对比分析
如果对延迟要求不高的情况下,建议使用Spark Streaming,丰富的高级API,使用简单,天然对接Spark生态栈中的其他组件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高…
“高效记录收支明细,按时间轻松查找借款信息“
我们有时候要去查找借款信息,只记得住借款记录的日期,想通过日期来进行筛选出借款信息,要如何进行操作?今天就让小编来教教大家要如何操作。
第一步,我们要打开【晨曦记账本】,并登录账本。 第二步&#x…
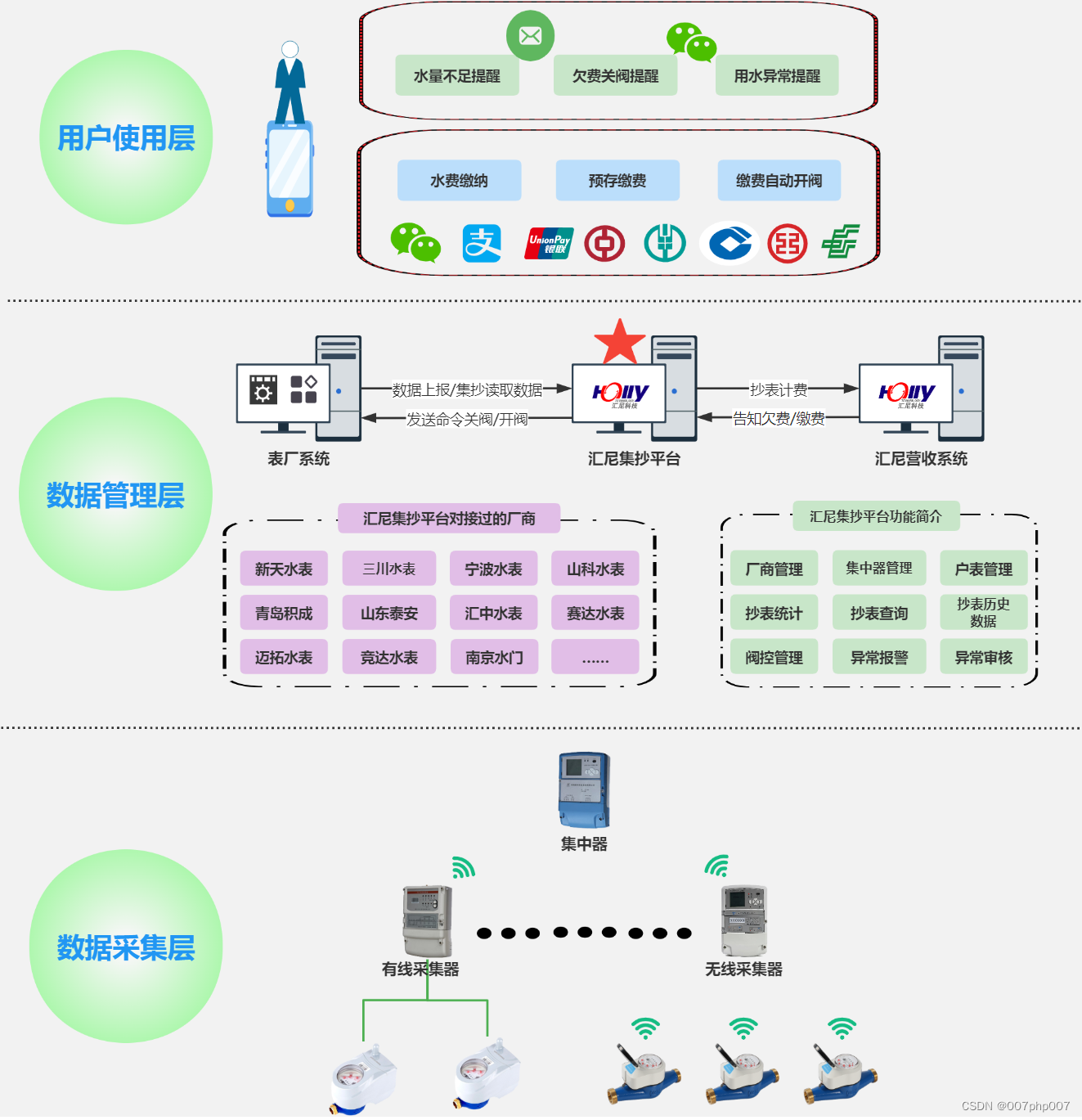
水务系统的设计与实现
水务系统是指对供水和排水进行全面管理的系统,本文将介绍水务系统的设计原则、技术架构以及实践经验,帮助读者了解如何构建一个高效、稳定的水务系统。
正文:
1. 系统设计原则
在设计水务系统时,需要遵循以下设计原则ÿ…
cdn与云服务器有什么区别
CDN和云服务器是两种不同的网络产品,它们的主要区别在于产品定位和功能。CDN是一种构建在现有网络基础之上的智能虚拟网络,专门用于提升网站应用在不同地区的网络变化,从而提升网站的打开速度。而云服务器则是云计算服务体系中的一项主机产品…
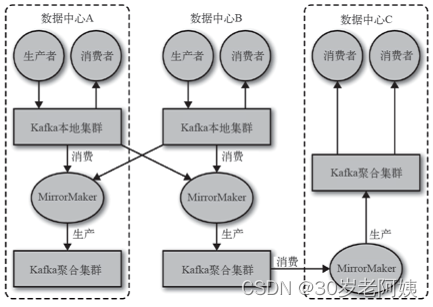
大数据-Storm流式框架(六)---Kafka介绍
Kafka简介
Kafka是一个分布式的消息队列系统(Message Queue)。
官网:Apache Kafka
消息和批次
kafka的数据单元称为消息。消息可以看成是数据库表的一行或一条记录。
消息由字节数组组成,kafka中消息没有特别的格式或含义。
消息有可选的键&#x…
大数据处理 - 双层桶划分
分桶法简介其实本质上还是分而治之的思想,重在“分”的技巧上!适用范围: 第k大,中位数,不重复或重复的数字基本原理及要点: 因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围…
大数据-Storm流式框架(三)--Storm搭建教程
一、两种搭建方式
1、storm单节点搭建
2、完全分布式搭建
二、storm单节点搭建
准备
下载地址:Index of /dist/storm
1、环境准备:
Java 6
Python 2.6.6
2、上传、解压安装包
3、在storm目录中创建logs目录
mkdir logs
启动
./storm help
…
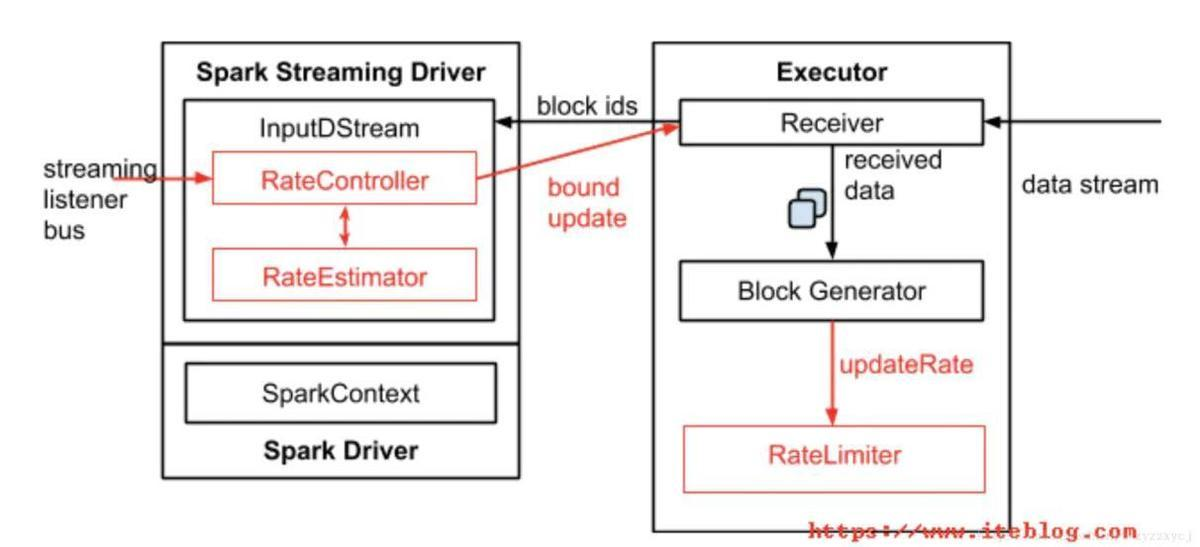
对比Flink、Storm、Spark Streaming 的反压机制
分析&回答
Flink 反压机制
Flink 如何处理反压?
Storm 反压机制 Storm反压机制 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了…
Java 版本storm-demo
1.创建maven项目,并引入storm的依赖
<dependency><groupId>org.apache.storm</groupId><artifactId>storm-core</artifactId><version>1.1.0</version></dependency>2.新建NumberSpout.java
public class Number…
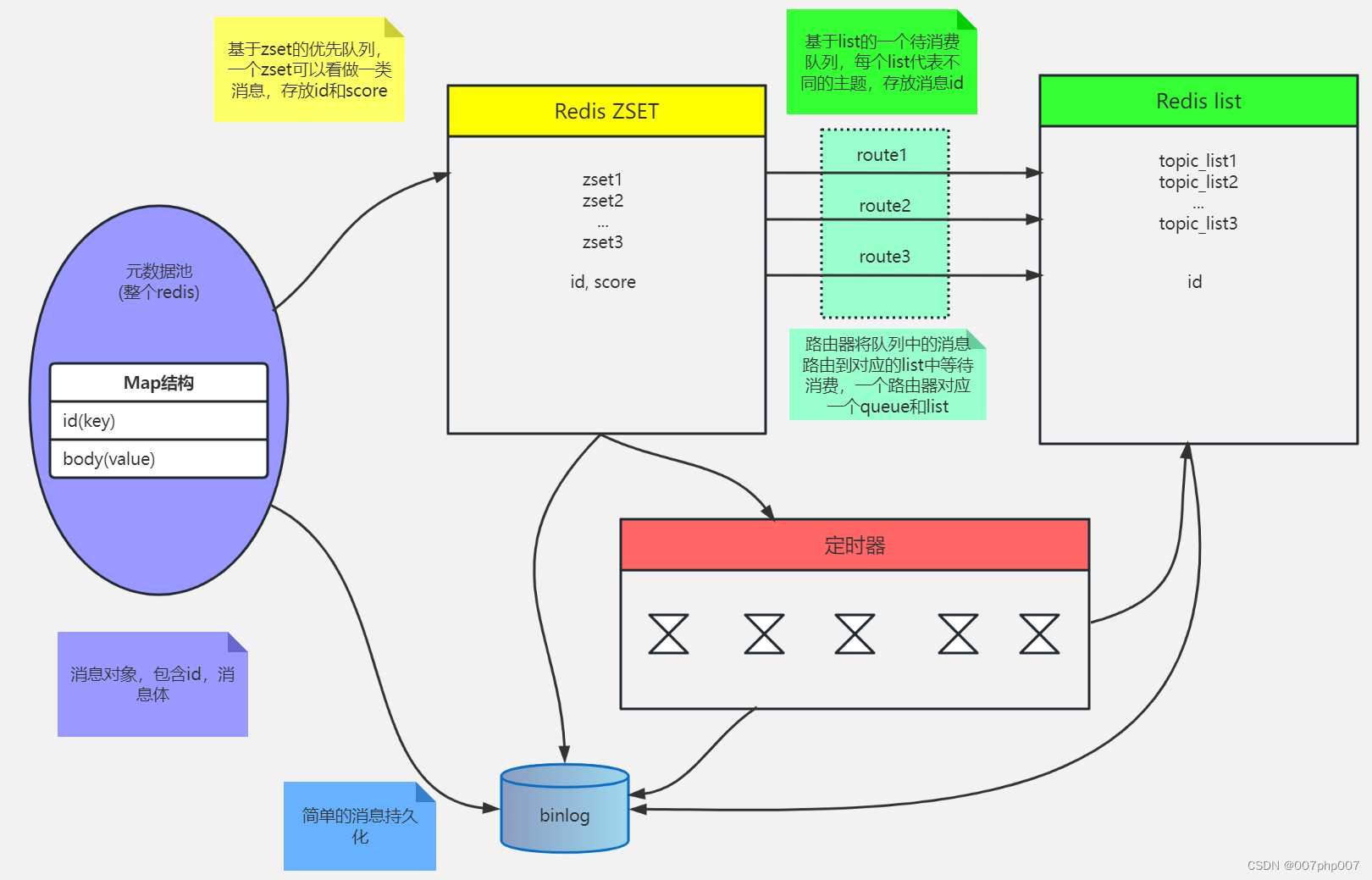
Redis 服务集群、哨兵、缓存及持久化的实现原理和应用场景
Redis 是一种高性能的键值存储系统,已经成为了许多企业和互联网公司的核心技术之一。本文将介绍 Redis 的服务集群、哨兵以及缓存实现原理和应用场景,以帮助读者更好地理解和使用 Redis。
引言: 随着互联网应用规模不断扩大,Redi…
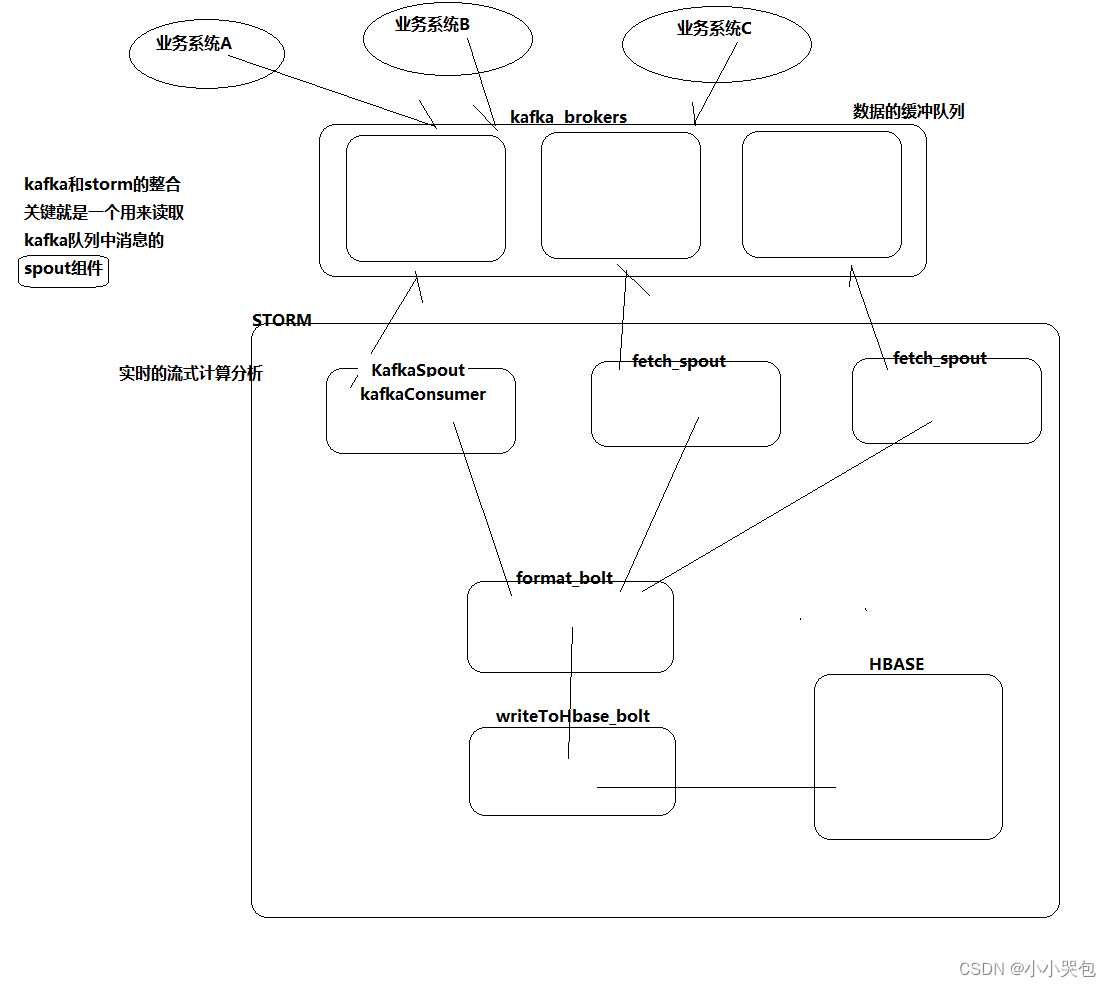
kafka笔记要点和集群安装、消息分组、消费者分组以及与storm的整合机制
kafka笔记
1/kafka是一个分布式的消息缓存系统 2/kafka集群中的服务器都叫做broker 3/kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间…
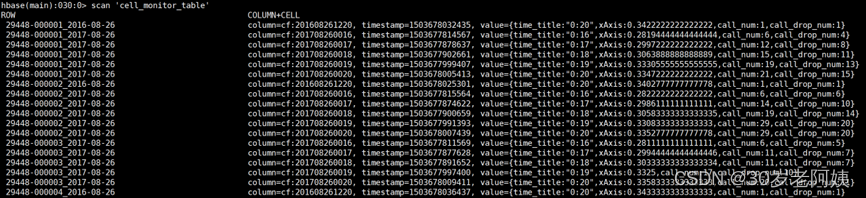
大数据-Storm流式框架(八)---Storm案例
中国移动项目部署文档
一、项目架构 二、启动集群
1、启动Zookeeper集群
2、启动Hbase(完全分布式需要先启动Hadoop集群)
在conf/hbase-env.sh中设置JAVA_HOME
在conf/hbase-site.xml中,仅需要指定hbase和zookeeper写数据的本地路径。默…
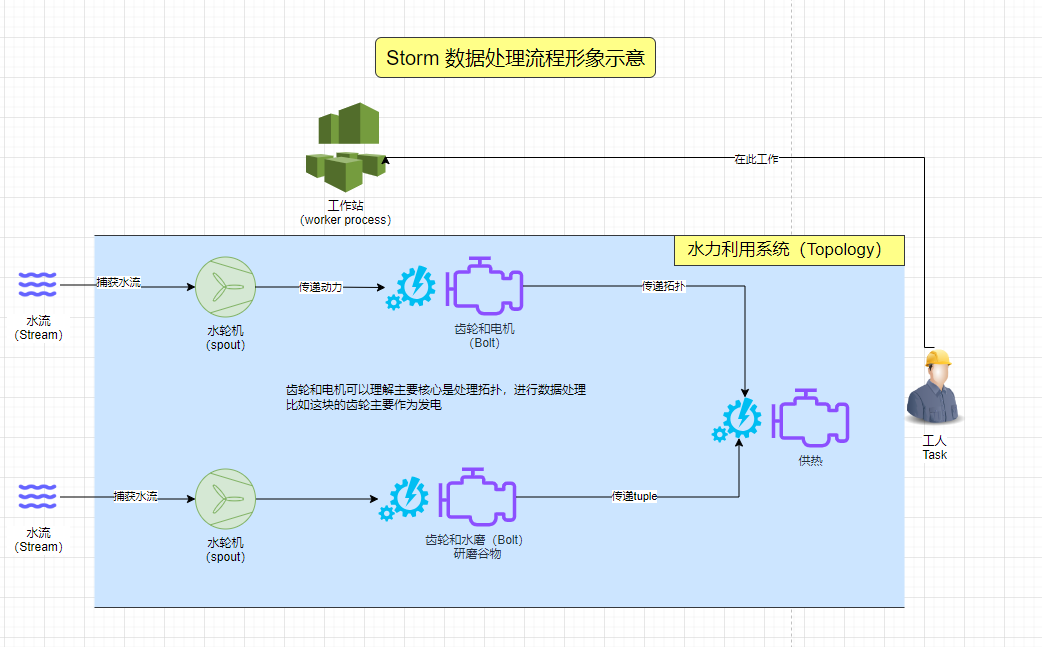
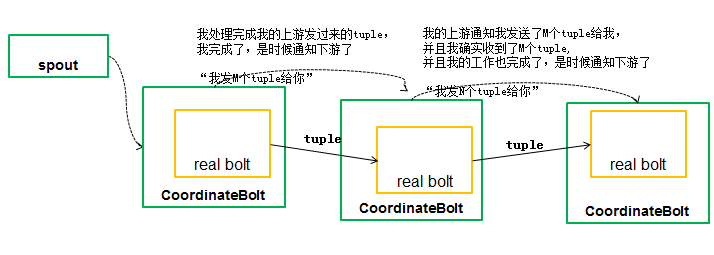
【Storm实战】1.1 图解Storm的抽象概念
文章目录 0. 前言1. Storm 中的抽象概念1.1 流 (Stream)1.2 拓扑 (Topology)1.3 Spout1.4 Bolt1.5 任务 (Task)1.6 工作者 (Worker) 2. 形象的理解Storm的抽象概念2.1 流 (Stream)2.2 拓扑 (Topology)2.3 Spout2.4 Bolt2.5 任务 (Task)2.6 工作者 (Worker)场景1场景2 3.参考文档…
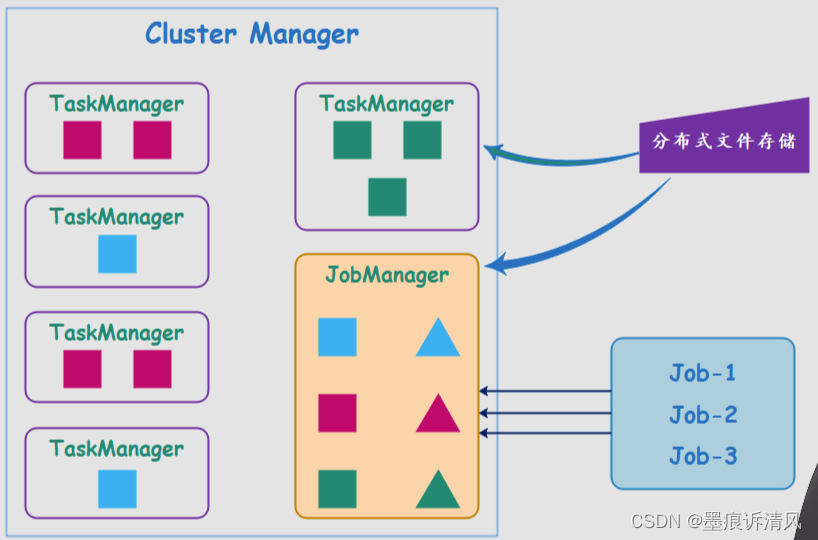
Hadoop、Spark、Storm、Flink区别及选择
hadoop、spark、storm、flink如何选择
hadoop和spark是更偏向于对大量离线数据进行批量计算,提高计算速度storm和flink适用于实时在线数据,即针对源源不断产生的数据进行实时处理。至于storm和flink之间的区别在于flink的实时性和吞吐量等要比storm高。…

单病种质量管理上报系统该如何选型
01案例分析
以某三级医院为例,全院2020年需上报的病例总数约为7140份,在国家直报系统用时2个月上报总数约为1200份,按此进度计算,所有病例上报完毕还需耗时约10个月。
经过多层筛选,该院最终选择并使用了米软单病种质…
一键去除文件名中的空格,轻松解决文件命名烦恼!
你是否曾经为文件名中的空格而烦恼?这些空格可能会在传输、存储和搜索文件时带来各种问题。为了解决这个问题,本文将向你介绍几种实用的方法,让你轻松去除文件名中的空格,让文件命名变得更加简单!
首先,我…
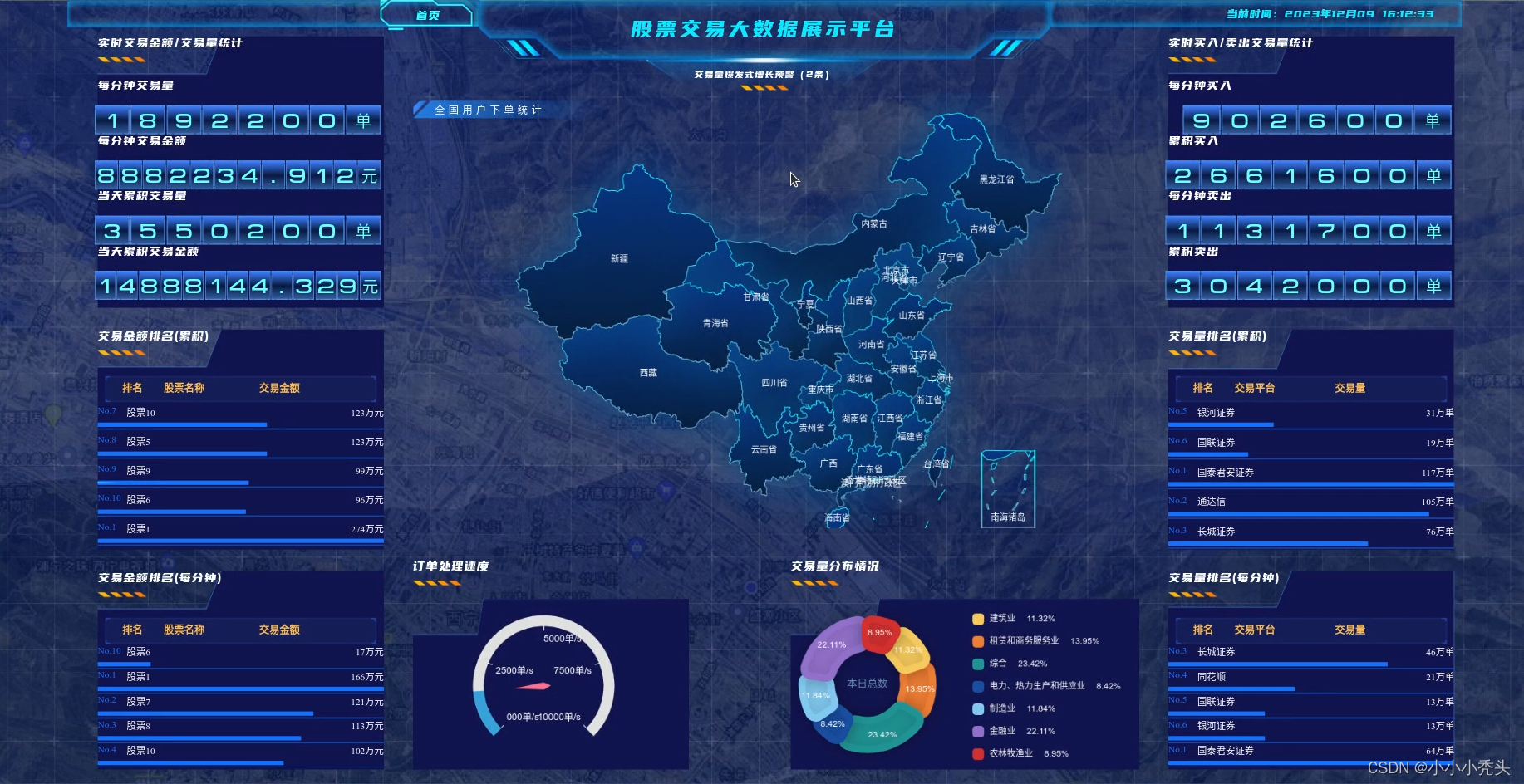
股票交易信息实时大屏(Kafka+storm+Redis+DataV)
目录
引言
需求分析:
思路
数据源:
数据传输:
数据处理:
数据统计:
数据可视化:
数据提取:
技术栈
技术实现
前端界面搭建 布局:
组件: 通信&#x…
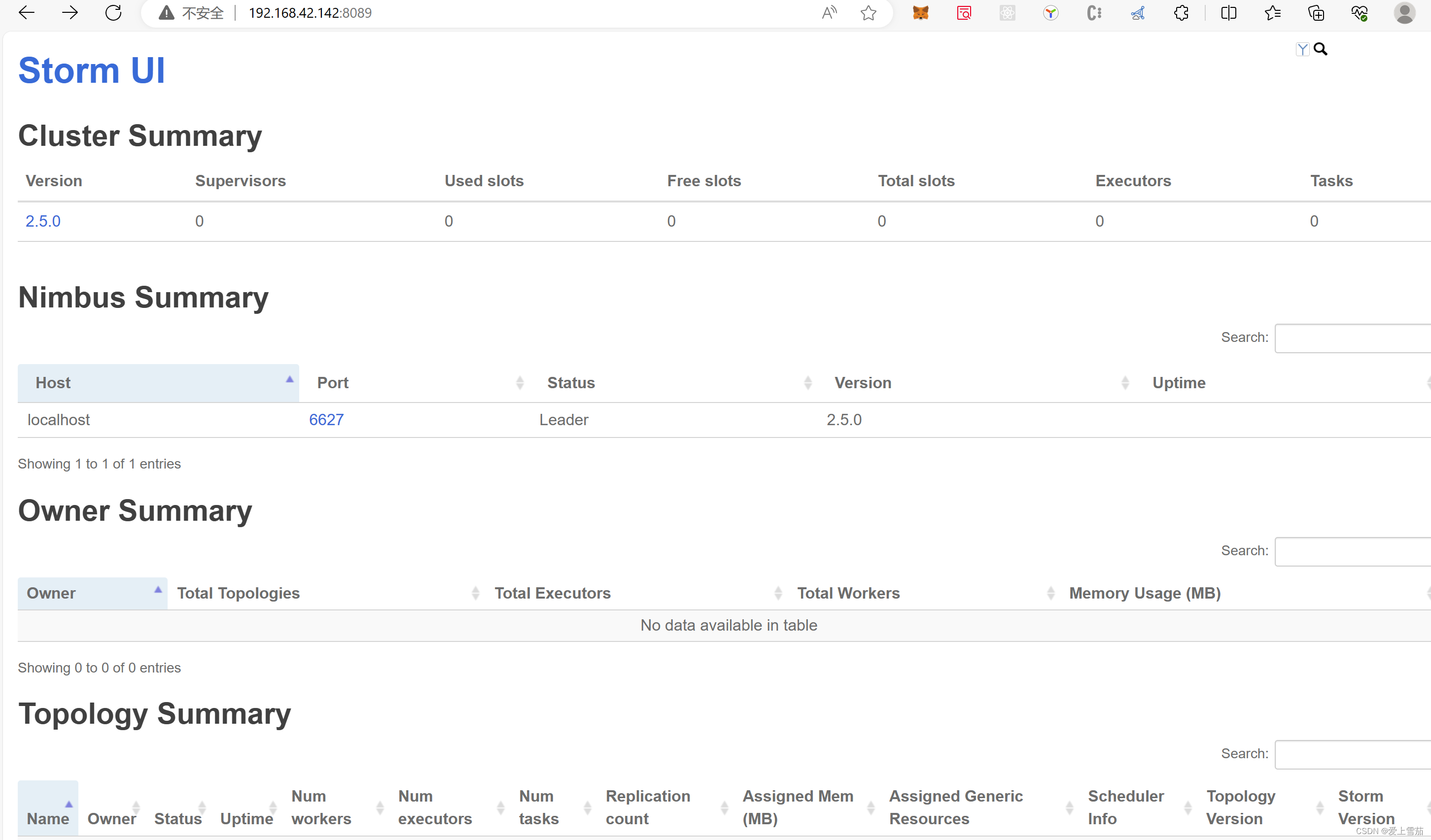
Apache Storm 2.5.0 单机安装与配置
1、下载storm 2.5.0
2、需要安装python3,并且设置python3的环境变量
3、修改storm.yaml配置 storm.zookeeper.servers:- "node4"
# - "server2"
#
# nimbus.seeds: ["host1", "host2", "host3"]
# nimbus…
Storm常见错误及处理方法
1. 发布topologies到远程集群时,出现Nimbus host is not set异常
原因是Nimbus没有被正确启动起来,可能是storm.yaml文件没有配置,或者配置有问题。
解决方法:打开storm.yaml文件正确配置:nimbus.host: "xxx.xx…

使用Storm实现实时大数据分析
当今世界,公司的日常运营经常会生成TB级别的数据。数据来源囊括了互联网装置可以捕获的任何类型数据,网站、社交媒体、交易型商业数据以及其它商业环境中创建的数据。考虑到数据的生成量,实时处理成为了许多机构需要面对的首要挑战。我们经常…
从Storm和Spark 学习流式实时分布式计算的设计
0. 背景 最近我在做流式实时分布式计算系统的架构设计,而正好又要参加CSDN博文大赛的决赛。本来想就写Spark源码分析的文章吧。但是又想毕竟是决赛,要拿出一些自己的干货出来,仅仅是源码分析貌似分量不够。因此,我将最近一直在做的…
大数据技术之Storm的安装与配置
大数据技术之Storm的安装与配置
这篇文章深入研究了大数据技术中实时计算系统 Apache Storm 的安装与配置过程。首先,文章介绍了 Apache Storm 在大数据处理中的重要性,强调其在实时数据处理领域的关键作用。随后,详细阐述了如何在系统中进行…


Jstorm2.1.1集群安装
Strom是什么? storm是Twitter开源的的一个分布式的,容错的实时流计算系统,用来处理大数据系统中一些实时计算业务。strom本身是一个类似Hadoop的MapReduce的计算框架,最大不同在于storm是一个启动后不会停止的服务,除…
“一键导出,高效整理:将之前的部分记录导出!“
亲爱的朋友们,你们是否曾经为了导出之前的记录而感到烦恼?冗长的过程,无法精确控制的选项,实在让人感到心力交瘁。但现在,我们为你带来一种全新的解决方案,让你的工作更轻松,更高效!…
storm文档(5)----创建storm新项目
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41542267
源地址:http://storm.apache.org/documentation/Creating-a-new-Storm-project.html 本文主要介绍如何配置开发的storm项目。步骤如下:
1、将storm jar包加到c…
storm文档(6)----storm手册目录
转载请注明:http://blog.csdn.net/beitiandijun/article/details/41543189
源地址:http://storm.apache.org/documentation/Documentation.html storm基础知识
l Javadoc
l 概念
l 配置
l 保证消息处理机制
l 容错性能
l 命令行客户端…
storm多个bolt之间多对一或一对多下发
由于业务的关系,bolt之间的下发一般分为以下几种: 1.一对一,单线条 2.多对一,汇聚式 3.一对多,发散式 至于说 多对多,交叉式,就可以看成是多个一对多来处理,原理也一样 一对一&#…
VIOOVI深度发问:精益思想是什么?
精益思想是什么?
精益思想最早是从丰田生产体系中得到启发的,通俗来说就是用最小的投入去创造最大的价值:通过消除浪费,减少资源投入,加上人力资源上的优化、设备管理上的改善和一些小的地方创新,尽可能多…

Storm的ack机制 重复消费
Storm的ack机制的弊端可能会导致重复消费
参考文献:https://www.cnblogs.com/intsmaze/p/5918087.html
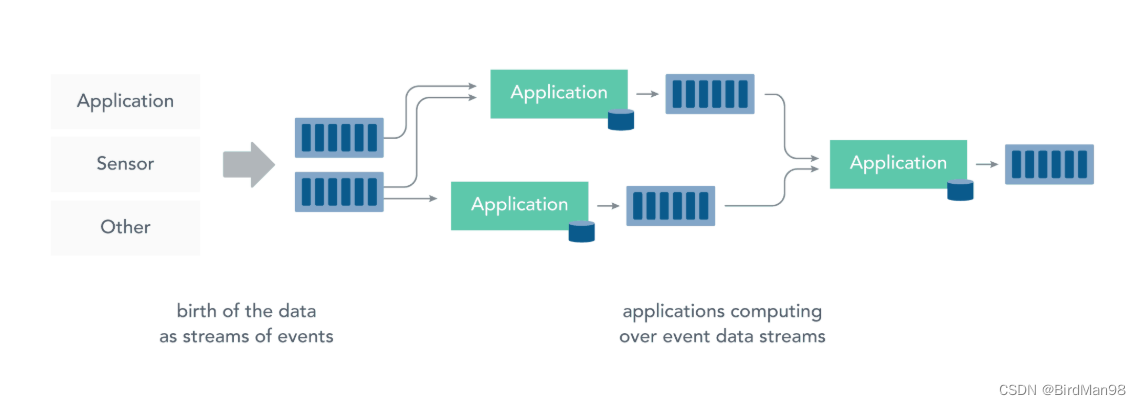
【Storm】【二】Storm和流处理简介
Storm和流处理简介 一、Storm1.1 简介1.2 Storm 与 Hadoop对比1.3 Storm 与 Spark Streaming对比1.4 Storm 与 Flink对比二、流处理2.1 静态数据处理2.2 流处理一、Storm
1.1 简介
Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理…
一文对比storm与spark(特性与应用场景)
背景 随着实时数据的增加,对实时数据流的需求也在增长。更不用说,流技术正在引领大数据世界。使用更新的实时流媒体平台,用户选择一个平台变得很复杂。Apache Storm和Spark是该列表中最流行的两种实时技术。让我们根据它们的功能比较Apache S…
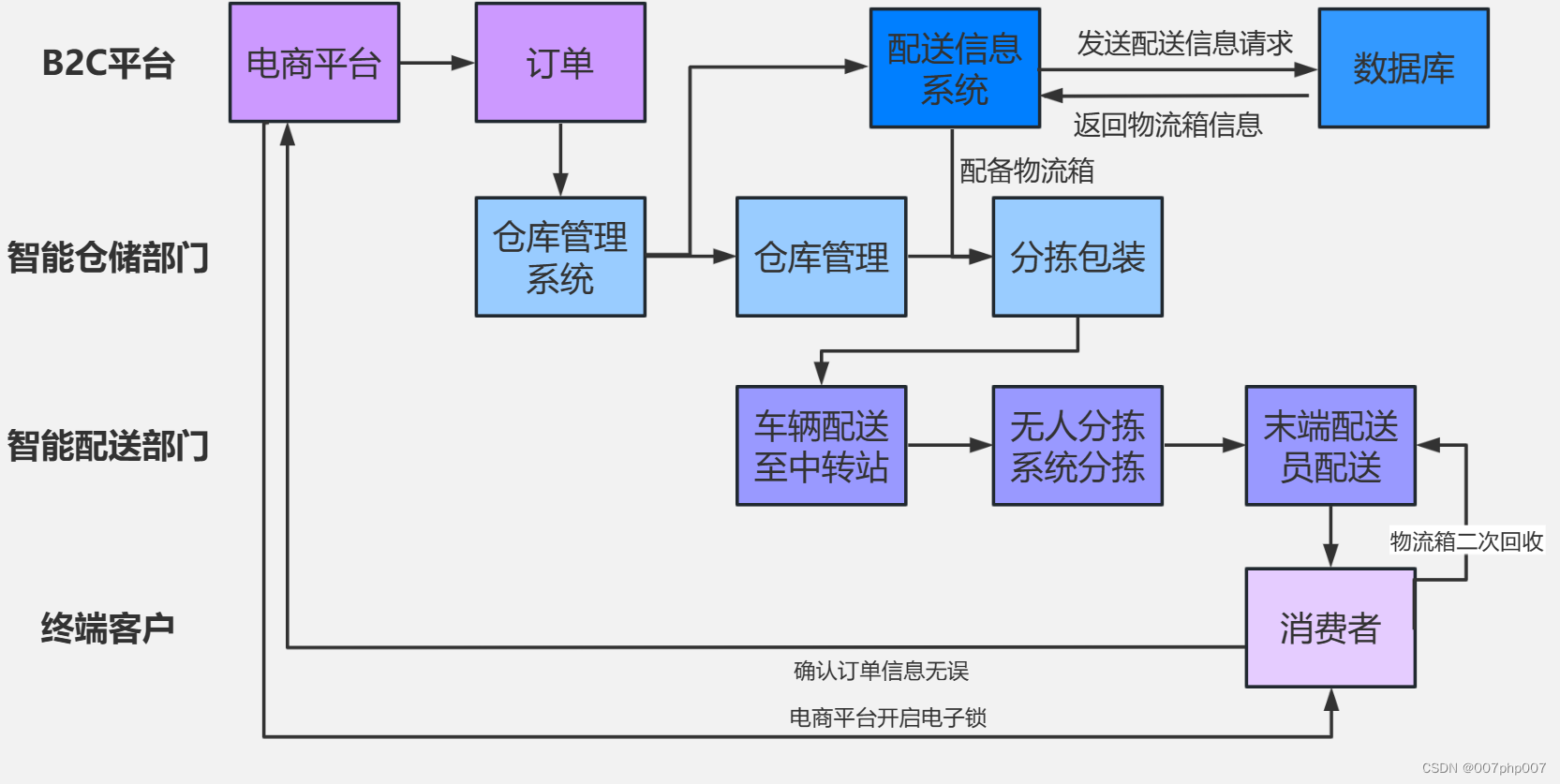
提升物流效率,快递平台实战总结与分享
随着电商行业的蓬勃发展,物流配送服务变得愈发重要。快递平台作为连接电商企业和消费者的桥梁,扮演着至关重要的角色。本篇博客将分享快递平台实战经验,总结关键要点,帮助物流从业者提升物流效率、优化服务质量。
### 快递平台实…
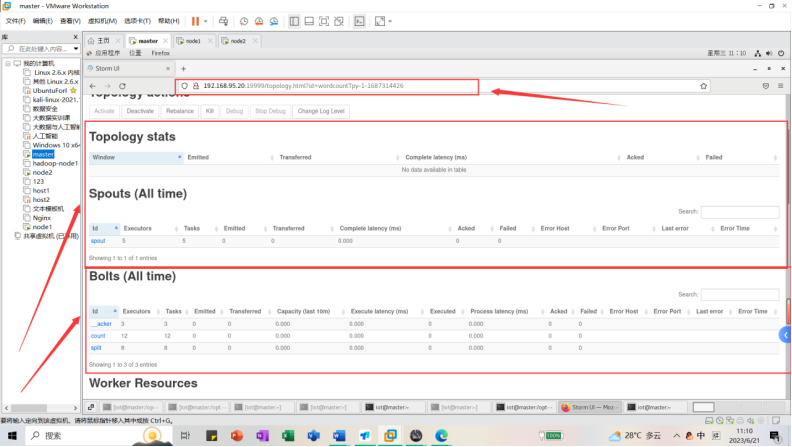
云计算与大数据——Storm配置及运行WordCountTopology(保姆级教程!)
云计算与大数据——Storm配置及运行WordCountTopology(保姆级教程!)
前言
当今世界正处于云计算和大数据的快速发展阶段,而Storm作为一种高效、可靠的实时计算框架,受到了广泛的关注和应用。在这篇文章中,…
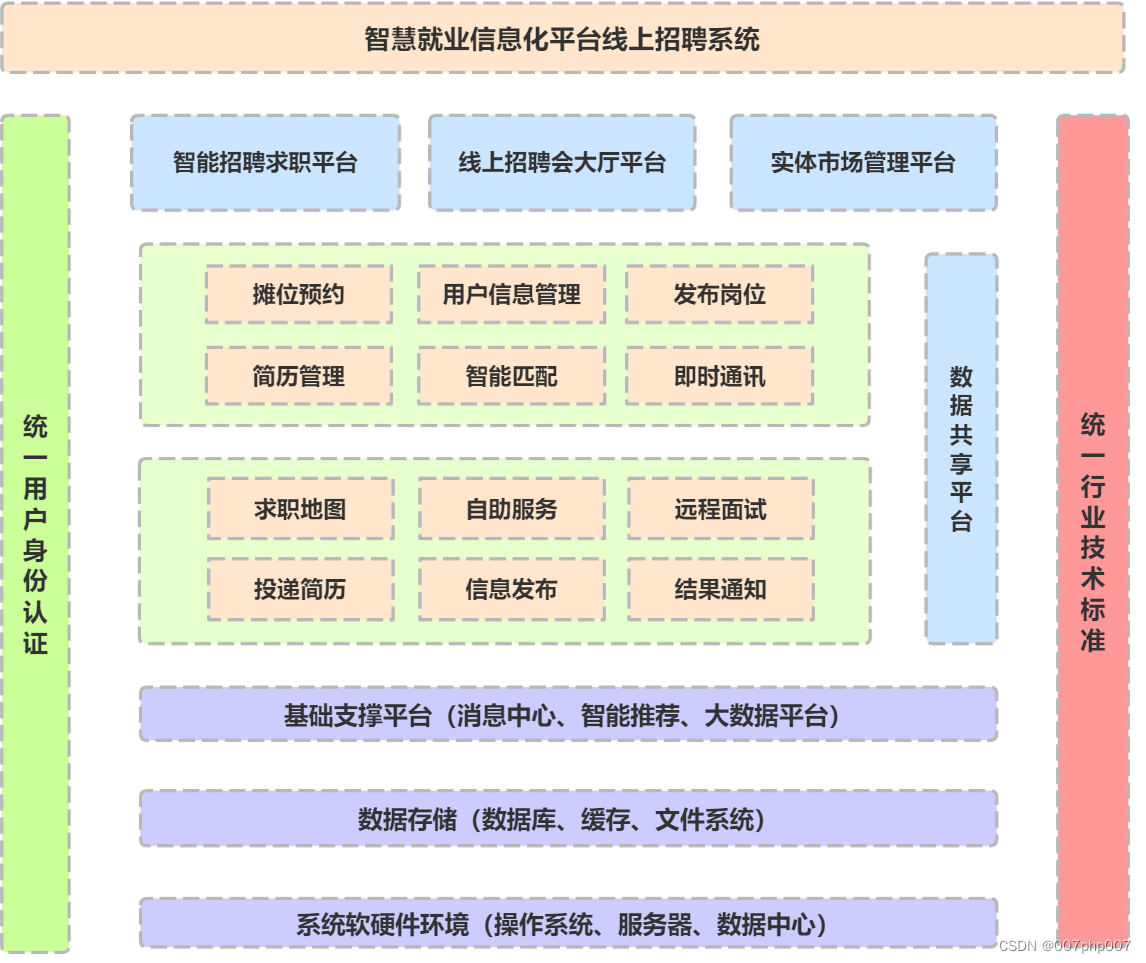
招聘系统架构的设计与实现
在当今竞争激烈的人才市场中,有效的招聘系统对企业吸引、筛选和管理人才至关重要。本文将探讨招聘系统的架构设计与实现,帮助企业构建一个高效、可靠的人才招聘平台。
## 1. 系统架构设计
### 1.1 微服务架构 招聘系统通常采用微服务架构,将…
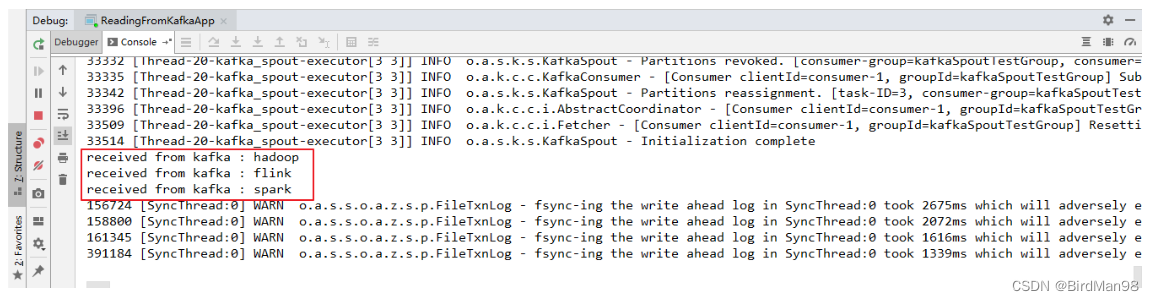
【Storm】【五】Storm集成Kafka
Storm集成Kafka 一、整合说明二、写入数据到Kafka三、从Kafka中读取数据一、整合说明
Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下:
Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持;Storm Kafka …
看一眼常见数据处理的产品
Hadoop vs Spark
Hadoop 是一个分布式存储和计算框架,而 Spark 是一个基于内存的分布式计算框架。Hadoop 在存储大数据方面表现出色,而 Spark 在计算和处理大数据方面表现更快。另外,Hadoop 使用 MapReduce 处理数据,而 Spark 使…
storm文档(11)----搭建storm集群
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41684717
源地址:http://storm.apache.org/documentation/Setting-up-a-Storm-cluster.html 本文叙述了storm集群搭建和运行步骤。如果你打算在AWS上进行的话,可以使用st…
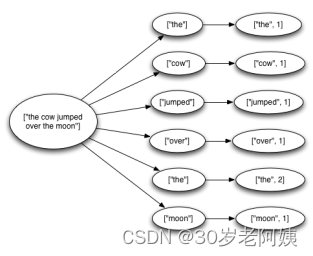
大数据-Storm流式框架(四)---storm容错机制
1、集群节点宕机
Nimbus服务器 硬件
单点故障?可以搭建HA jStorm搭建 nimbus的HA
nimbus的信息存储到zookeeper中,只要下游没问题(进程退出)nimbus退出就不会有问题,
如果在nimbus宕机,也不能提交…

大数据-Storm流式框架(一)
一、storm介绍 Storm是个实时的、分布式以及具备高容错的计算系统 Storm进程常驻内存(worker,supervisor,nimbus,ui,logviewer。。。)Storm数据不经过磁盘,在内存中处理Twitter开源的分布式实时…

Apache Storm 2.5.0 集群安装与配置
1、下载Apache Storm 2.5.0
https://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-2.5.0/
2、准备3台服务器
192.168.42.139 node1
192.168.42.140 node1
192.168.42.141 node2
3、配置host
[rootnode1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost…
storm trident api
Trident API partition本地操作,无需网络io 等同于pig的generate mystream.each(new Fields("b"), new MyFunction(), new Fields("d"))) public class MyFunction extends BaseFunction { public void execute(TridentTuple tuple, TridentCol…
实时计算大作业kafka+zookeeper+storm+dataV
第一章 总体需求
1.1.课题背景
近年来,大数据称为热门词汇,大数据分析随着互联网技术的发展愈加深入电商营销之
中,越来越多的电商企业利用大数据分析技术,利用信息化对产业发展营销方向进行确定,
对电子商务行…

Flume(NG)架构设计要点及配置实践
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG…

Storm集群执行Topology,JVM无法获取System的Property
现象
在Storm中需要用HikariCP处理Mysql的数据交互,配置文件放在了src\main\resources\下面 在拓扑启动前,把配置文件中的属性全部取出来,放到JVM中去,这样直接使用System.getProperty就可以拿到,不用写一些全局常量一些工具类。…
实时收集Storm日志到ELK集群
#### 背景我们的storm实时流计算项目已经上线几个月了,由于各种原因迟迟没有进行监控,每次出现问题都要登录好几台机器,然后使用sed,shell,awk,vi等各种命令来查询原因,效率非常低下,…
storm 文档(1)----文档主页
Storm documentation
源地址:http://storm.apache.org/documentation/Home.html Storm是分布式、实时运算系统。 类似于Hadoop提供一系列批处理的基本原则, Storm提供一系列实时运算的基本原则。Storm实现简单,可以使用任何语言进行编程&…
Apache Storm内部原理分析
本文算是个人对Storm应用和学习的一个总结,由于不太懂Clojure语言,所以无法更多地从源码分析,但是参考了官网、好多朋友的文章,以及《Storm Applied: Strategies for real-time event processing》这本书,以及结合自己…
有赞统一日志平台初探
【编者的话】从2015年初入职有赞以来,一直致力于后端服务开发,主要设计开发了监控系统Hawk,但这不是本次要分享的点。一个月前,负责日志平台Track的小伙伴寻求梦想出去创业了,有幸接手了日志平台,这对本人确…
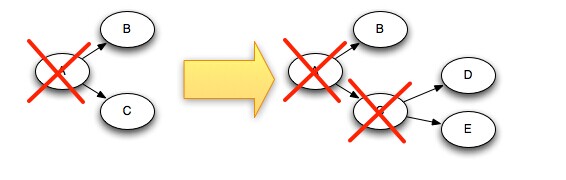
storm文档(9)----消息处理保证机制
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41577125
源地址:http://storm.apache.org/documentation/Guaranteeing-message-processing.html Storm保证:每条离开spout的消息都可以得到"fullyprocessed"。…
storm文档(12)----自己搭建storm集群
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41802543 ubuntu下 storm 安装步骤
安装storm之前首先需要安装一些依赖库:
zookeeper、JDK 6、python2.6.6、jzmq、zeromq
这些库所需要的依赖库不再一一笔述。 以下为具体安装过…
storm文档(7)----基本概念
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41546195
源地址:http://storm.apache.org/documentation/Concepts.html 本文介绍了storm的主要概念,并且给出相关链接供你查看更多信息。本文讨论的概念如下所示&#x…
storm文档(8)----配置文件说明
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41547569
源地址:http://storm.apache.org/documentation/Configuration.html storm由丰富的configure选项, 用来调整nibus、supervisor、以及运行时topologies的行为。某…
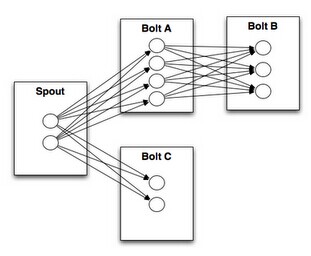
storm 文档(3)----入门指导
转载请注明出处:http://blog.csdn.net/beitiandijun/article/details/41517897 源地址:http://storm.apache.org/documentation/Tutorial.html 本文主要讲述了如何创建Storm topologies以及如何将它们部署在Storm集群中。Java是主要使用的语言࿰…
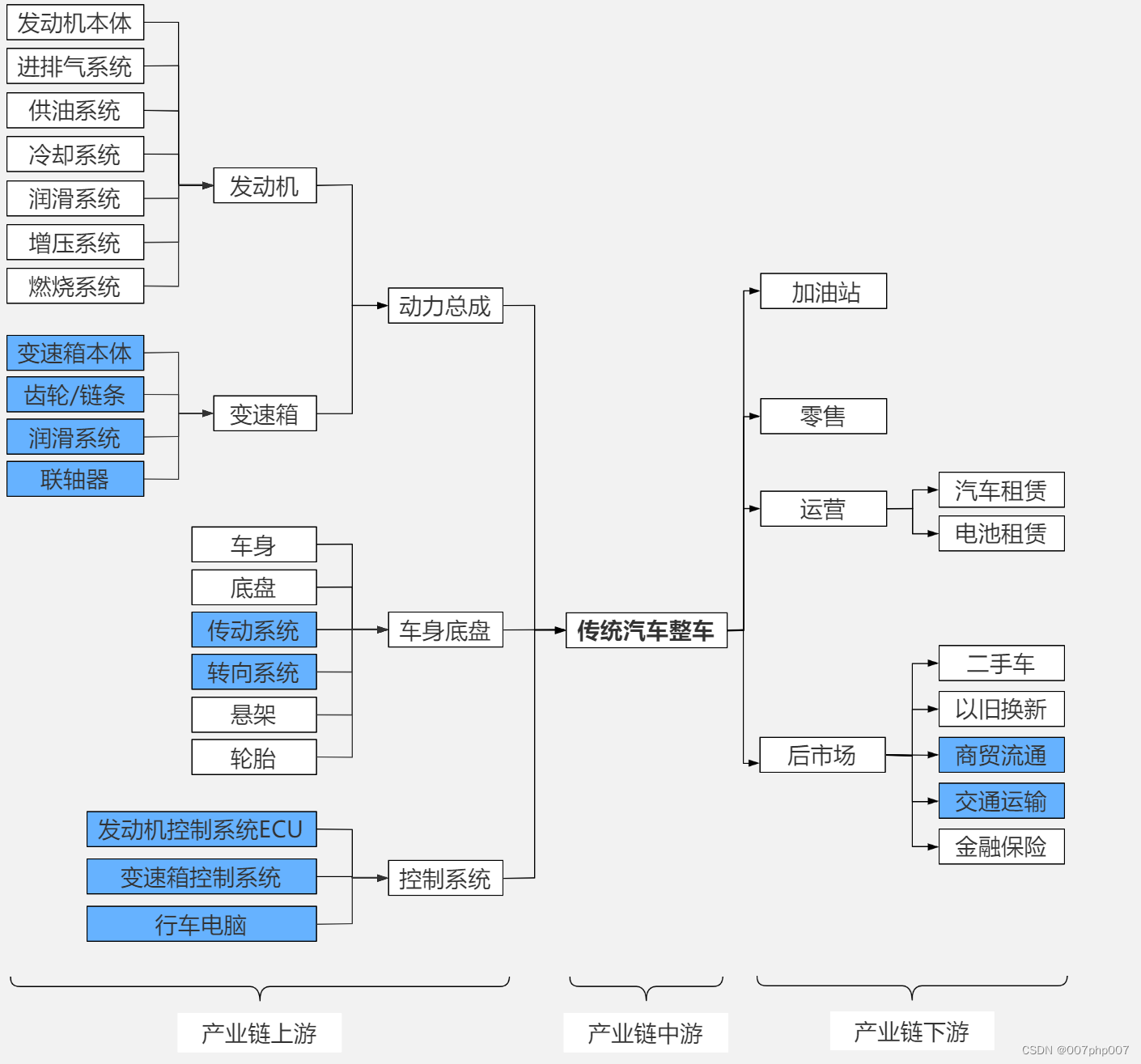
智慧回收与售后汽车平台架构设计与实现:打造可持续出行生态
随着汽车保有量的增加和环保意识的提升,汽车回收和售后服务成为了整个汽车产业链中不可或缺的一环。如何设计和实现一个智慧化的回收与售后汽车平台架构,成为了当前汽车行业关注的热点话题。本文将从需求分析、技术架构、数据安全等方面,探讨…

Python 学习之路 03 之循环
😀前言 欢迎来到 Python 循环和流程控制的基础教程!无论您是一名新手,还是希望复习 Python 编程的基本知识,这个教程都是一个非常好的资源。在这份教程中,我们将探索 Python 中的不同循环结构和流程控制机制࿰…
谷歌SEO适用于独立站优化的8个核心算法
对独立站实施的一切优化工作,均旨在向谷歌排名靠前算法规则的靠拢。日常优化工作就是使其越来越靠拢,无限靠拢。
换言之,谷歌SEO优化实质是将独立站网站做成符合谷歌排名靠前的规则这一个日常工作。
什么是谷歌SEO排名因素?
SE…

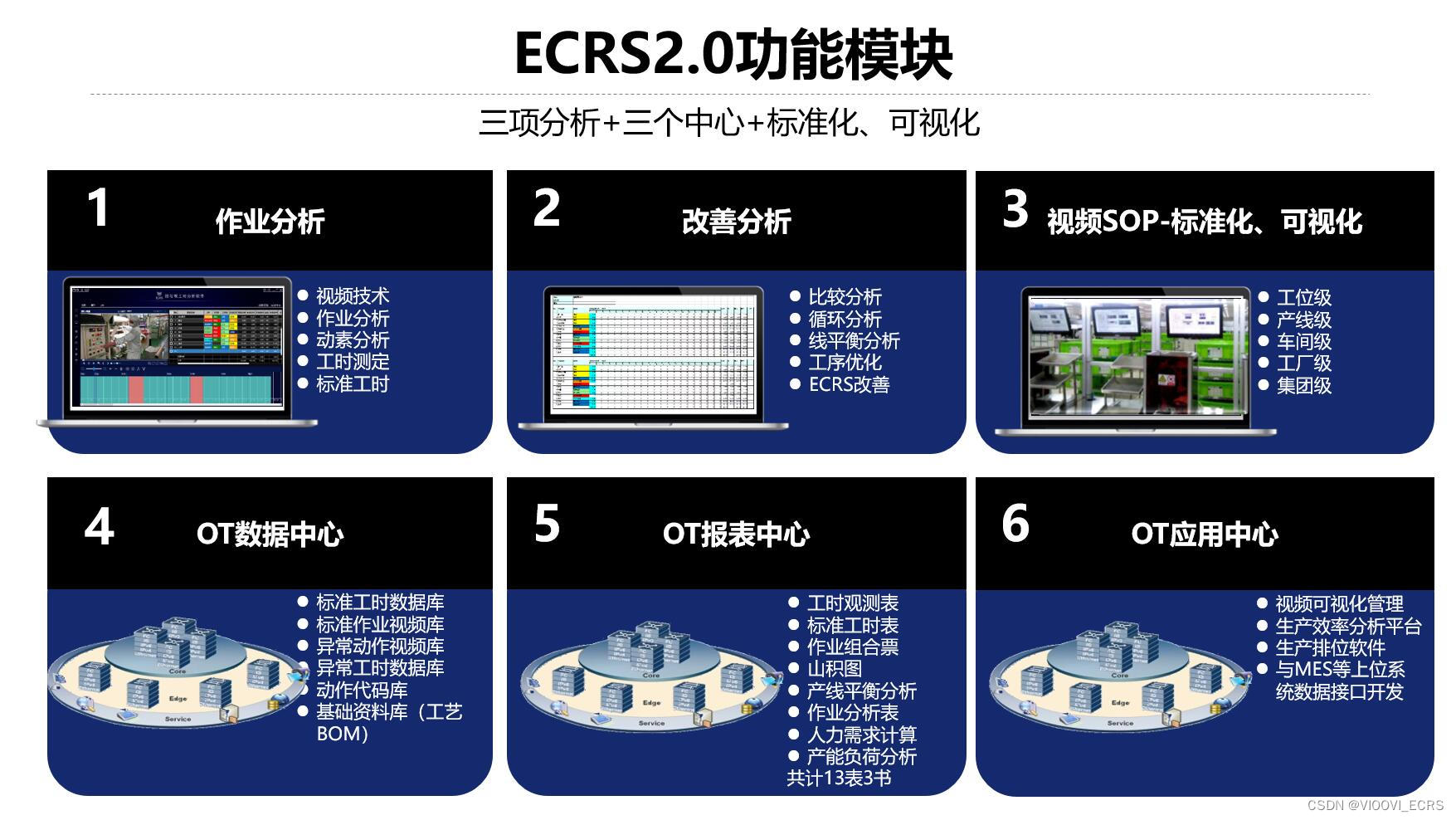
浅谈安全检查“三要素” ,一看二问三检测,ECRS工时分析软件
安全检查是企业搞好安全生产常用的主要方法和手段,检查能发现问题、解决问题、预防事故的发生。如何更好、更有效地开展安全检查,达到预定的目的,个人认为,在实施检查时,“一看、二问、三检测”是检查者必须要掌握和抓…
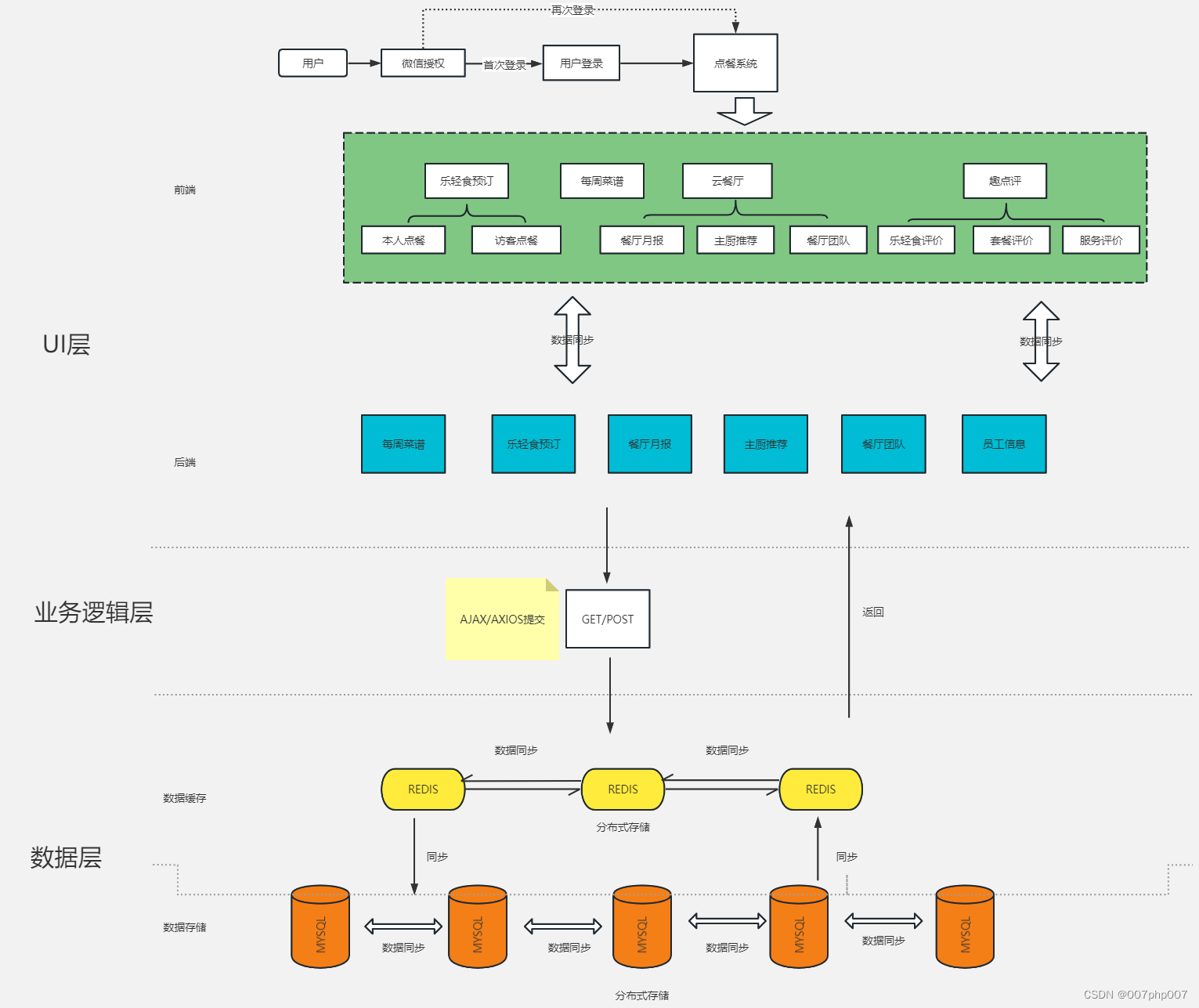
智慧餐饮系统架构的设计与实现
随着科技的不断发展,智慧餐饮系统在餐饮行业中扮演着越来越重要的角色。智慧餐饮系统整合了信息技术,以提高餐饮企业的管理效率、客户服务质量和市场竞争力。本文将探讨智慧餐饮系统架构的设计与实现,并探讨其在餐饮行业中的应用前景。
架构…
Vista 2.08: The storm chaser
A story about Mathew —— the storm chaser. "He is too young to understand his dream and the Harvard is just others dream put into his mind." "You dont have to chase for the happiness that defined by others. You must define your own happines…
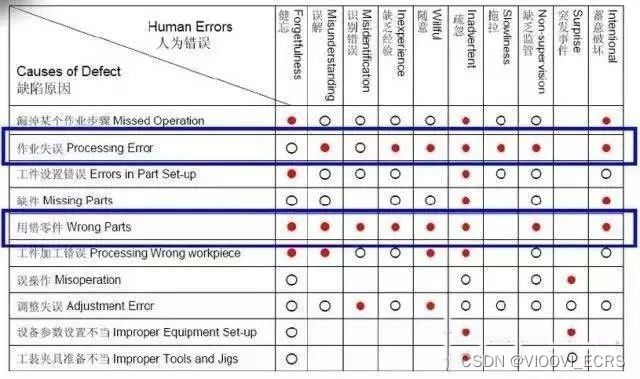
【精益生产】生产线上怎么做“防错”? 视与视ECRS工时分析软件
今天和大家聊一聊“防错”。在几年前,师父第一次把我独立地扔到一条座椅装配的生产线上去审核。
看些十几道工序,几十台设备在那有条不紊的运转着。款式各异的条码,测量设备上花花绿绿的信号看得我眼花缭乱,丝毫不知道该从哪下手…
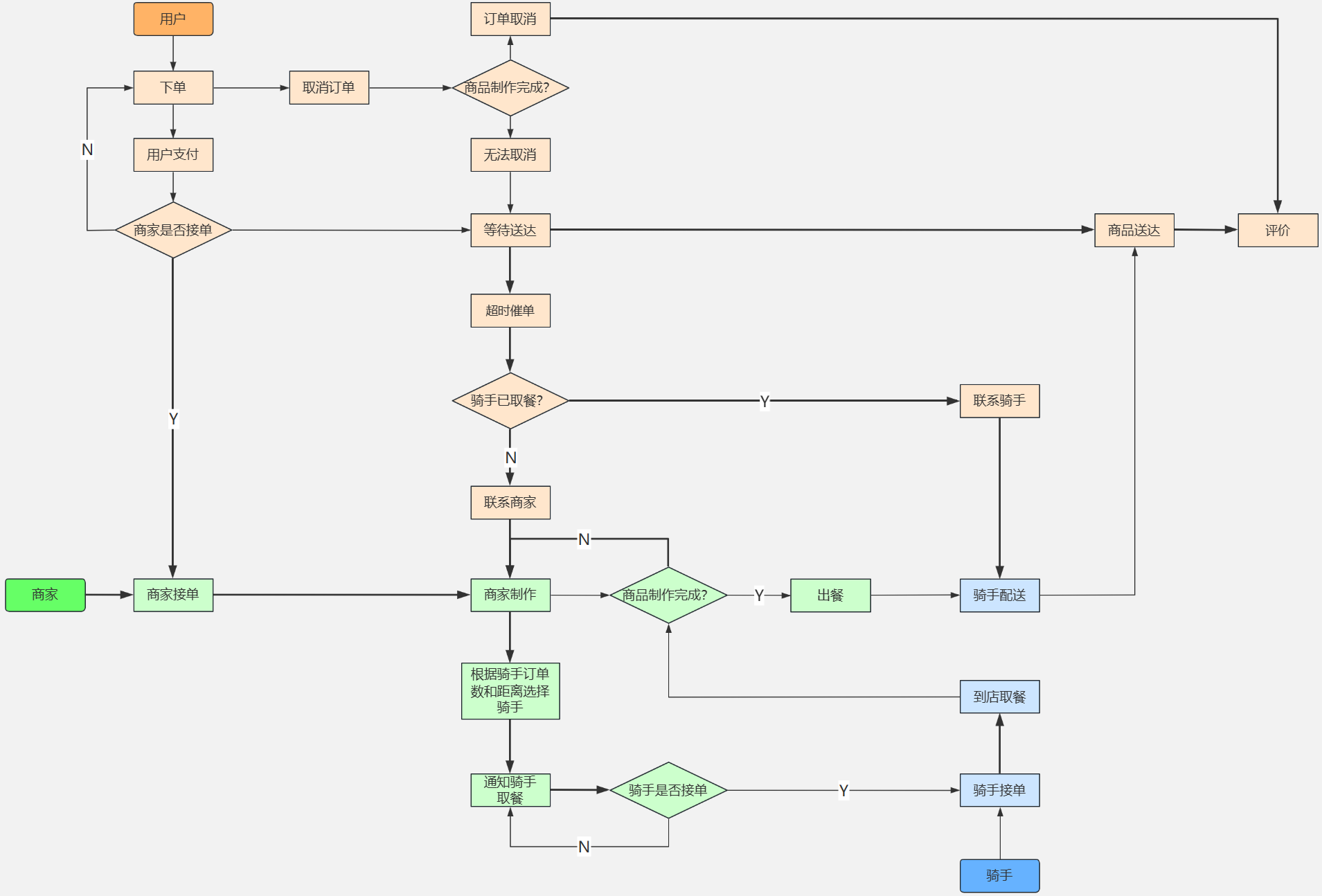
外卖平台订餐流程架构的实践
当我们想要在外卖平台上订餐时,背后其实涉及到复杂的技术架构和流程设计。本文将就外卖平台订餐流程的架构进行介绍,并探讨其中涉及的关键技术和流程。
## 第一步:用户端体验
用户通过手机应用或网页访问外卖平台,浏览菜单、选择…
storm集群的搭建
最近也是有朋友问我storm的问题,好长时间没玩storm了,今天就来简单的说一下吧,首先我们来看一下官网的图片,storm是完全实时的,就像水龙头打开后一样,会不停的往外面流水.所以他的延迟非常的低,这也是他的特点.然后先搭建storm集群吧,storm集群的搭建也比较简单. 然后来看一下s…
从Storm到Flink:大数据处理的开源系统及编程模型
开源系统及编程模型
基于流计算的基本模型,当前已有各式各样的分布式流处理系统被开发出来。本节将对当前开源分布式流处理系统中三个最典型的代表性的系统:Apache Storm,Spark Streaming,Apache Flink以及它们的编程模型进行详细…

Elasticsearch8集群部署
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 本文记录在3台服务器上离线搭建es8.7.1版本集群。
1. 修改系统配置
1.1 hosts配置
在三台es节点服务器加入hostname解析&…

大数据-Storm流式框架(五)---DRPC
DRPC
概念
分布式RPC(DRPC)背后的想法是使用Storm在运行中并行计算真正强大的函数。 Storm拓扑接收函数参数流作为输入,并为每个函数调用发送结果的输出流。
DRPC并不是Storm的一个特征,因为它基于Storm的spouts,bo…
大数据-Storm流式框架(二)--wordcount案例
一、编写wordcount案例
1、新建java项目
2、添加storm的jar包
storm软件包中lib目录下的所有jar包
3、编写java类
WordCountTopology.java
package com.bjsxt.storm.wc;import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.genera…

玩转大数据:2-揭秘Hadoop家族神秘面纱
1. 初识Hadoop家族
在当今的数字化时代,大数据已成为企业竞争的关键因素之一。为了有效地管理和分析这些庞大的数据,许多企业开始采用Hadoop生态系统。本文将详细介绍Hadoop生态系统的构成、优势以及应用场景。
首先,让我们来了解一下什么是…
Apache STORM工作原理详解
Apache Storm是一个分布式实时计算系统,允许用户在集群上运行流式数据处理应用程序。它的核心原理是将流式数据分割成多个小块,每个小块都会被分配给不同的计算节点进行处理,并且处理结果会被发送到下一个节点,直到达到最终结果。…

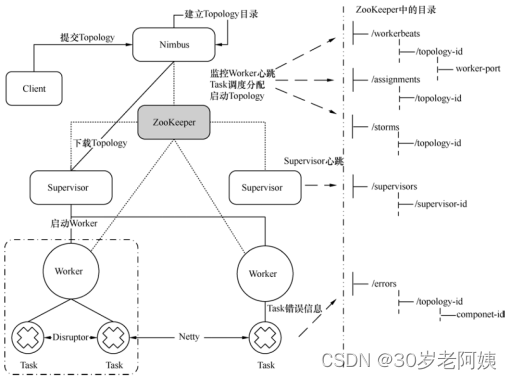
Apache Storm学习笔记(2)Apache Storm的组成部分及工作流程
Apache Storm体系结构
原则上,zookeeper应该在Nimbus和Supervisor之间,负责将集群状态信息以及Task和Supervisor映射关系存放在zookeeper集群上
Apache Storm的相关术语
Streams:是一个由无限制的Tuple序列组成,由传送方和接收方规定好传…

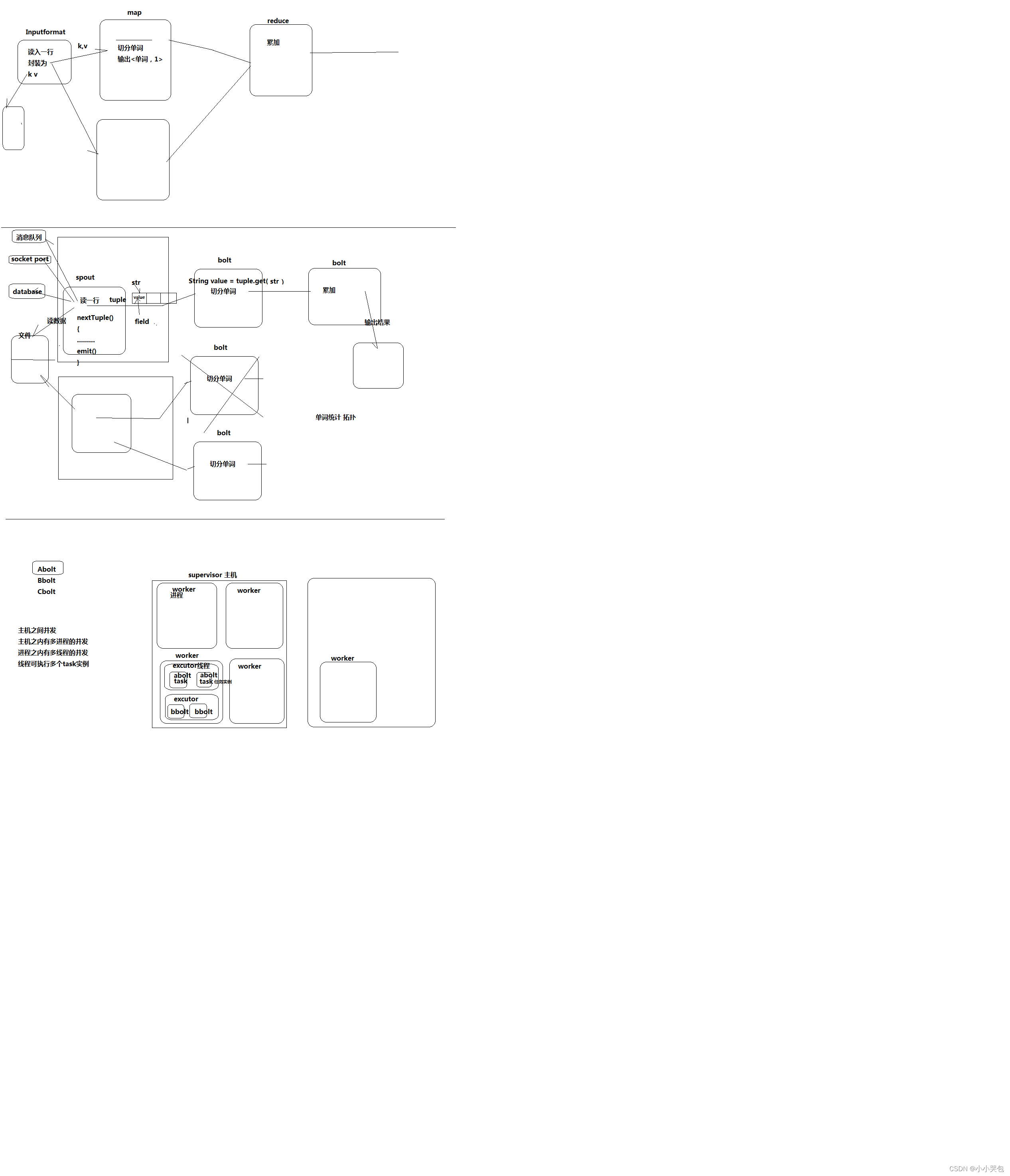
storm学习篇(二)—— 单词计数实例
利用storm实现简单的单词统计
添加依赖pom.xml
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation&qu…
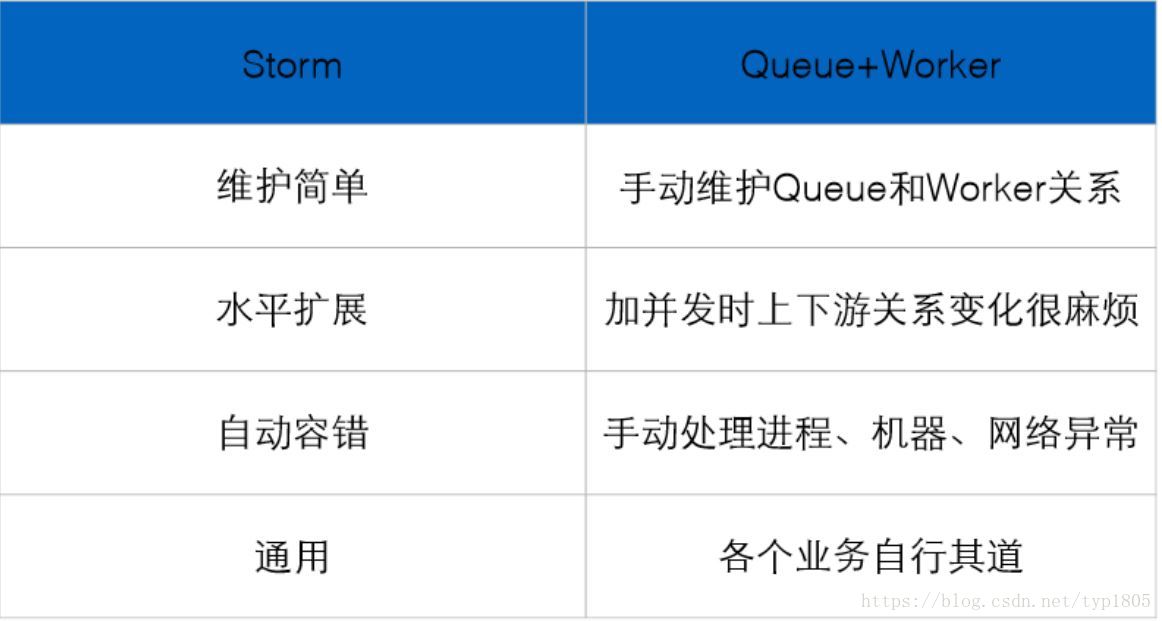
storm学习篇(一)
• storm是一个分布式的、容错的实时计算系统, • Storm实时低延迟,主要有两个原因: – storm进程是常驻内存的,不像hadoop里面是不断的启停的,就没有不断启停的开销。 – 第二点,Storm的数据是不…

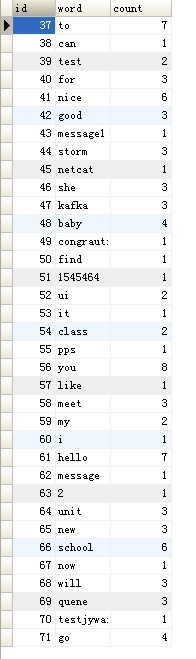
storm学习篇(三)——集成MySQL
以统计单词代码为例子,用jdbcClient直接执行SQL
添加依赖pom.xml
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instanc…

sop作业指导书怎么做?sop标准作业指导书用什么软件做?
自标准作业程序sop这个概念引入市场以来,现代生产企业纷纷开始打造自己的标准作业程序sop,然而在这个过程中,因为缺乏经验或者缺少相应的技术人员,导致遇到重重困难,其中最重要的一环sop作业指导书怎么做就难倒了不少企…

widget常设属性_常设桃树公园
widget常设属性I find it very easy to forget the world we live in. I grew up in North Atlanta, near the Chattahoochee, and spent a huge portion of it riding bikes to the river, going to some park on the river, or otherwise being around it. I’ve lived into…